
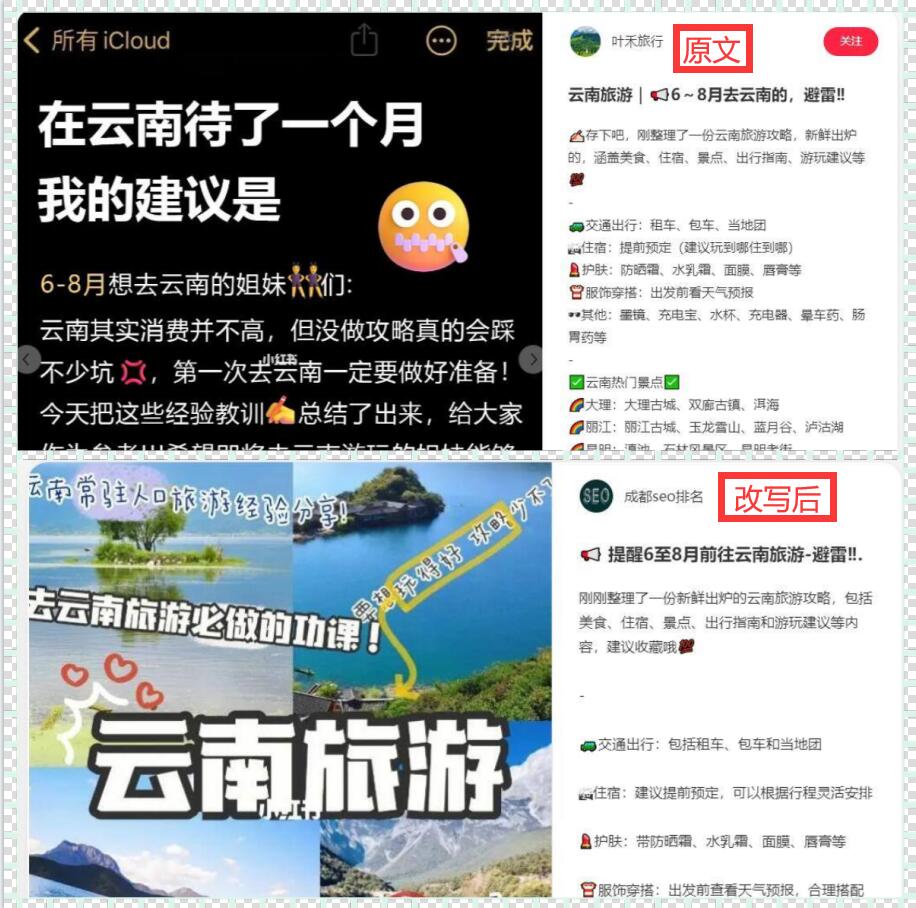
在互联网时代,数据被认为是新的石油,因为它具有无限的潜力和价值。对于许多企业和个人来说,获取并分析数据是至关重要的。然而,获取数据并不总是容易的事情,特别是当数据散落在各个网站上时。这时候,爬虫就成为了一种强大的工具。

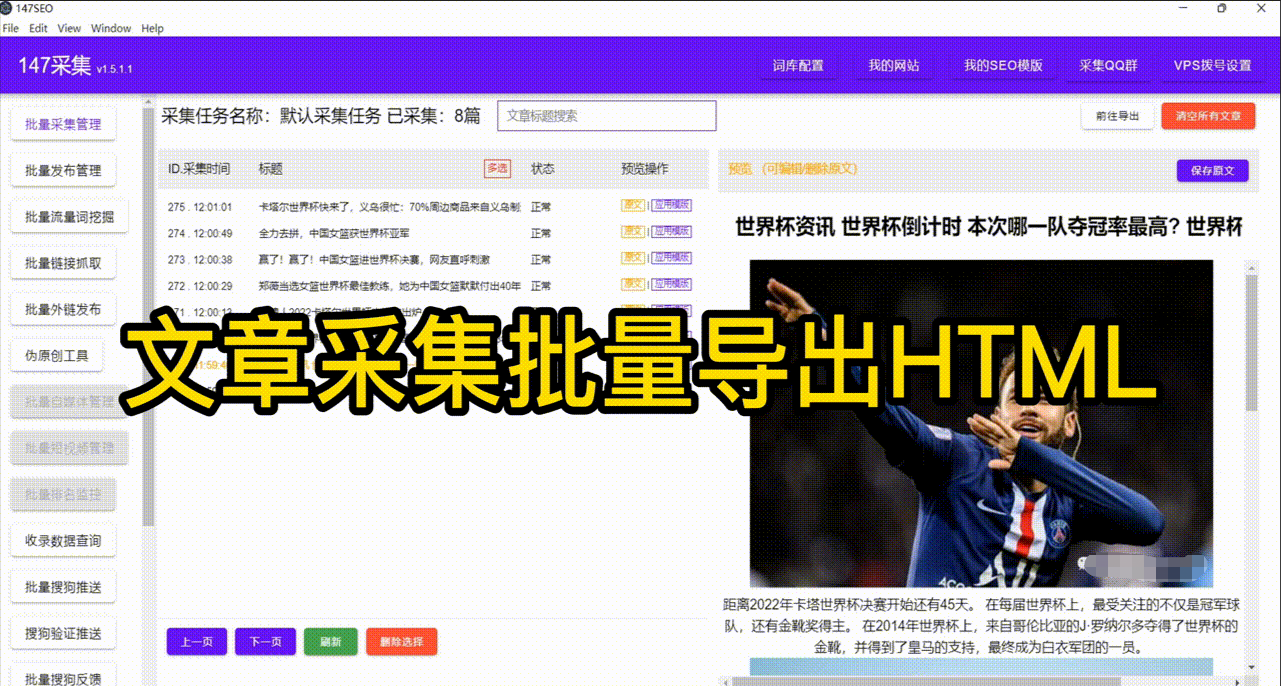
爬虫是一种模拟人类浏览器访问网页并提取数据的程序。它可以自动访问网页、抓取页面内容,从中提取数据并存储在本地。爬虫可以帮助我们从海量的网页中快速、准确地获取想要的数据。那么如何从零开始学习使用爬虫爬取数据呢?接下来,我将分享一些有用的教程ZY。
1.学习Python编程语言:在开始学习爬虫之前,你需要掌握一门编程语言。Python是一个非常适合初学者的编程语言,它有简洁的语法和强大的数据处理能力。你可以通过zaixian教程、shiping课程或参加培训班来学习Python。
2.理解HTML和CSS:在爬取网页数据之前,你需要了解HTML和CSS的基本知识。HTML是一种标记语言,用于描述网页的结构,而CSS用于控制网页的样式。掌握这两种技术将使你能够更好地理解网页的结构和内容。
3.学习HTTP协议:HTTP协议是用于在客户端和服务器之间传输数据的协议。了解HTTP协议的工作原理,包括请求和响应的结构、状态码和头部信息,将帮助你更好地理解网页的交互过程。
4.使用爬虫框架:Python有许多优秀的爬虫框架,如Scrapy和BeautifulSoup。这些框架可以帮助你更轻松地编写爬虫程序,并提供了许多有用的功能,如处理JavaScript渲染的页面、自动翻页和数据解析等。
5.学习数据解析和存储:使用爬虫爬取到的数据通常以HTML、XML或JSON等格式存在。你需要学会使用适当的工具来解析这些数据,并将其存储在适当的文件或数据库中,以便后续分析和处理。

6.遵守法律和道德规范:在使用爬虫爬取数据时,你需要遵守相关的法律和道德规范。尊重网站的隐私政策和使用条款是非常重要的,避免对网站造成过大的访问负担或侵犯他人的合法权益。
通过以上的学习和实践,你将能够掌握使用爬虫爬取数据的基本技能。不过,需要注意的是,爬虫技术和相关法规都在不断发展和变化,因此持续学习和保持更新是非常重要的。
总而言之,学习使用爬虫爬取数据是一项有挑战性但又非常有价值的技能。它可以帮助你获取大量的数据,并为你的工作或项目提供有力的支持。希望本文提供的教程ZY能够帮助你快速入门并取得成功!