蜘蛛爬取网站内容但是不收录的原因是?
 最新资讯
最新资讯  战国AI
战国AI  发布时间:2025-04-12
发布时间:2025-04-12  浏览: 次
浏览: 次 为什么蜘蛛爬取网站内容,却不收录?这是每个网站管理员和SEO优化者都曾面临过的疑问!我们常常看到搜索引擎的蜘蛛如风般爬过网站的每个角落,许多内容依旧未能顺利被收录。这种情况可能让人感到困惑,甚至沮丧。到底是什么原因导致蜘蛛爬取了我们的网页内容,却没有选择将其收录到搜索引擎的数据库中呢?

在我们深入之前,大家需要了解,搜索引擎蜘蛛的主要任务是收集互联网上的信息,并通过一定的算法和规则来决定哪些内容有价值、哪些内容需要被收录。这个过程中有很多因素会影响到蜘蛛是否最终选择收录页面。咱们就来一起分析,为什么网站内容被爬取却没有收录的那些常见原因。

1. 网站结构与蜘蛛爬行的难度
大家可能并没有意识到,网站的结构对于蜘蛛爬行至关重要。假如网站结构混乱、链接深度过多,蜘蛛在爬取内容时可能会遇到困难,甚至无法完整访问网站的所有页面。如果网站没有清晰的内链结构,蜘蛛很容易就会迷失方向,造成一些页面无法被及时抓取。

针对这一问题,解决方法很简单,那就是优化网站结构,确保每个页面都能通过合理的链接被蜘蛛顺利访问。例如,站长AI就可以通过一键批量发布,快速将内容分享到多个平台,这样不仅能增加页面的曝光率,也能帮助蜘蛛快速发现新的内容,提高收录率。

2. 内容质量和重复问题
很多时候,蜘蛛虽然爬取了页面,但因为内容质量不高或存在重复内容,它会选择不收录这些页面。搜索引擎非常重视内容的原创性和有价值性,如果你的网页只是复制粘贴的内容或者充斥着大量的无意义信息,蜘蛛在爬取后就会认为这些页面不值得收录。
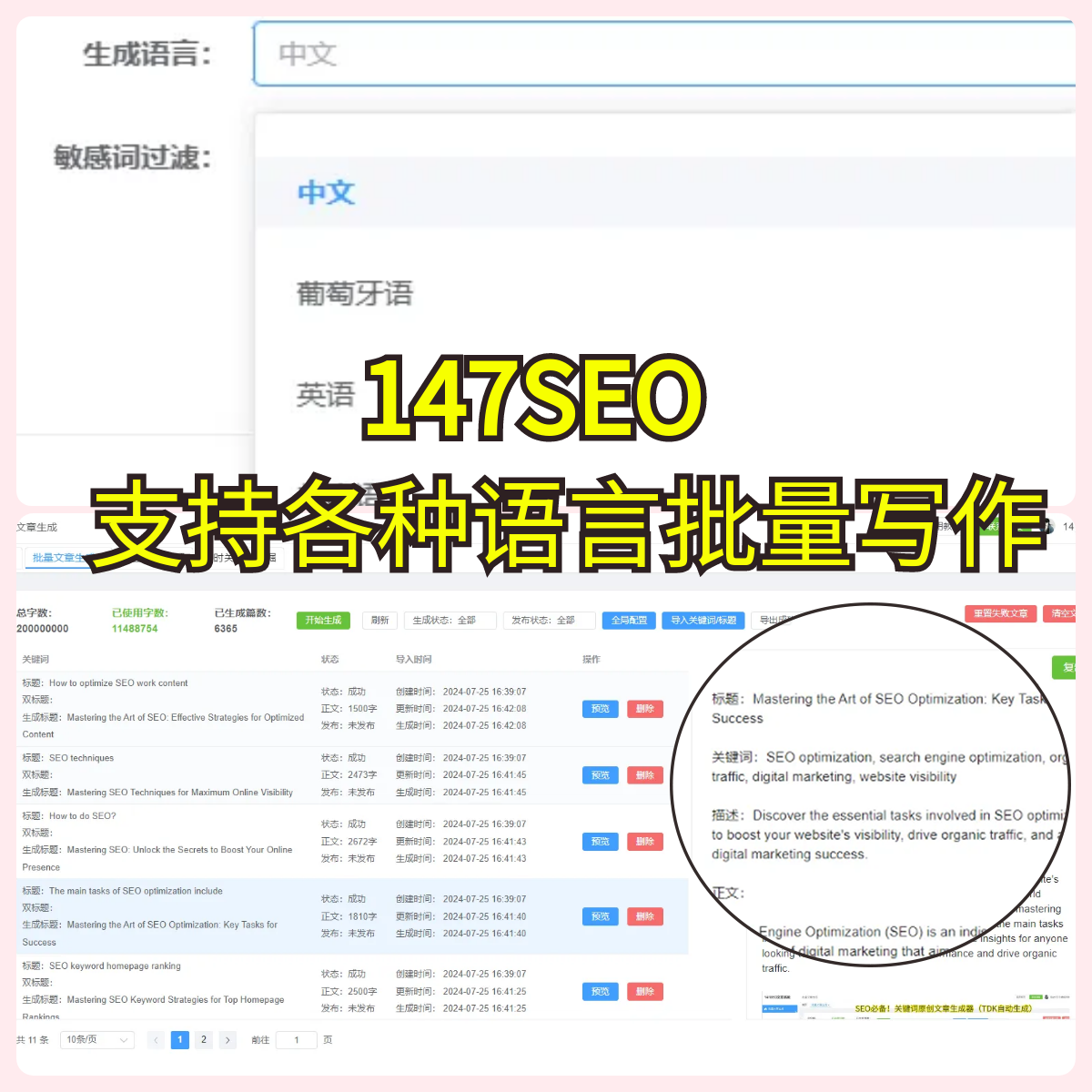
解决方案就是提高内容的质量,避免重复内容,并尽可能提供独特、有价值的信息。可以通过实时关键词功能,找到当前热门的搜索话题,从而优化你的内容,使其更加贴合用户需求。
3. robots.txt 文件的限制
如果你没有仔细检查网站的robots.txt文件,它可能会无意中阻止蜘蛛的爬行。这个文件是用来告诉搜索引擎哪些页面可以爬取,哪些不能爬取。如果错误地禁止了重要页面,蜘蛛虽然能访问到网站,但会被告知不允许抓取这些内容,最终也就无法被收录。
在这种情况下,解决方案非常简单:检查并修改robots.txt文件,确保没有误设置禁止访问的规则。如果你不确定如何操作,可以使用像宇宙SEO这样的工具,自动检查和优化网站的SEO设置,避免类似问题的发生。
4. 页面加载速度慢
页面加载速度慢也是导致蜘蛛不收录页面的一个常见原因。蜘蛛对于网页的抓取是有限制的,如果页面加载速度过慢,蜘蛛可能会选择放弃爬取,尤其是当你的网站含有大量大图片、视频等资源时。这样一来,页面虽然被蜘蛛访问了,但却没有足够的时间进行完整抓取和收录。
提升页面加载速度是解决这一问题的关键。通过压缩图片、启用缓存以及优化网站的代码,您可以有效提高页面的加载速度,使蜘蛛能够更快速地抓取内容并进行收录。
5. 缺乏外部链接支持
外部链接(也叫反向链接)对搜索引擎的蜘蛛爬行起着至关重要的作用。如果网站没有足够的外部链接指向,蜘蛛可能会认为这些内容缺乏权威性和价值,从而选择不进行收录。
如何解决这一问题?增强网站的外部链接建设,通过合作伙伴、社交媒体、博客等途径增加指向网站的链接流量。借助像好资源SEO这样的工具,可以帮助你更高效地进行外链分析与建设,提升网站的整体权重和收录率。
6. 不符合搜索引擎的质量标准
每个搜索引擎都有自己的质量标准,这些标准通常包括内容的原创性、页面的易用性、用户体验等。如果你的网页不符合这些标准,蜘蛛抓取到内容后,就可能会判断其质量较差,从而不收录。
想要提高页面的收录率,除了要提升内容质量外,还需要优化网页的用户体验,确保页面不仅美观而且易于操作。可以使用一些工具来分析和改善页面的SEO表现,避免触及搜索引擎的质量红线。
结尾:细节决定成败
总结起来,蜘蛛虽然抓取了网页内容,却没有收录的原因有很多,可能是网站结构复杂、内容重复、加载速度慢、缺少外链,甚至是设置错误的robots.txt文件。每一个小小的细节都可能影响最终的收录结果。作为站长和SEO优化者,我们要从多个角度去优化网站,确保每一篇高质量的内容都能够顺利被蜘蛛抓取和收录。
"成功是细节的积累,失败也是如此。" 只有在不断调整和优化的过程中,才能让网站的内容得到应有的关注和排名。让我们从今天开始,关注那些影响收录的小细节,让蜘蛛更加喜欢你的内容吧!
